PyTorch入门学习:4-Back Propagation
Back Propagation 反向传播
1 Introduction
- 对于简单的神经网络,我们可以使用解析式来计算梯度。
- 但是对于复杂的神经网络,我们无法使用解析式来计算梯度,因此需要使用反向传播算法。
- 每个层单独计算梯度并不复杂,而复合后,梯度的计算就变得复杂起来。
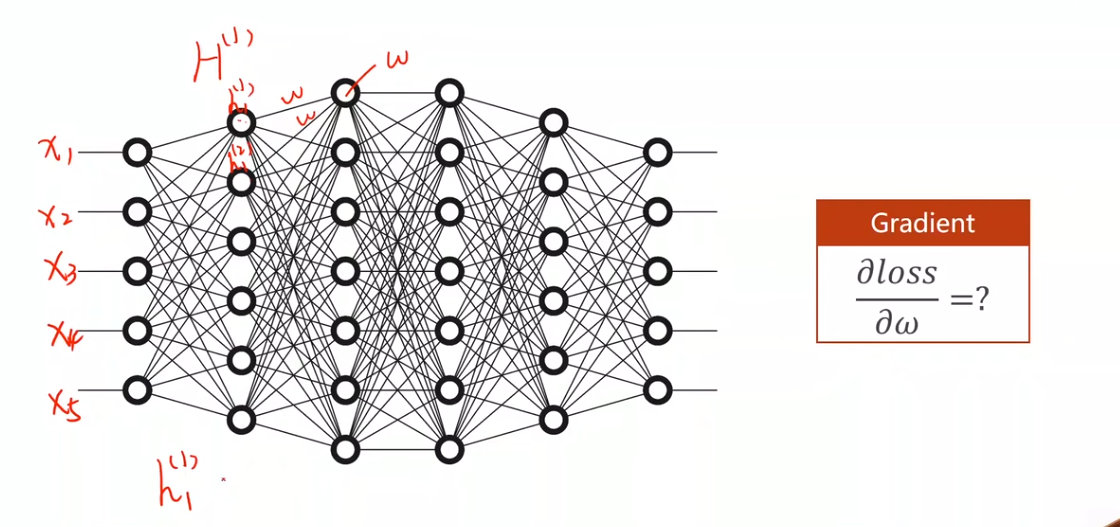
2 Computational Graph 计算图
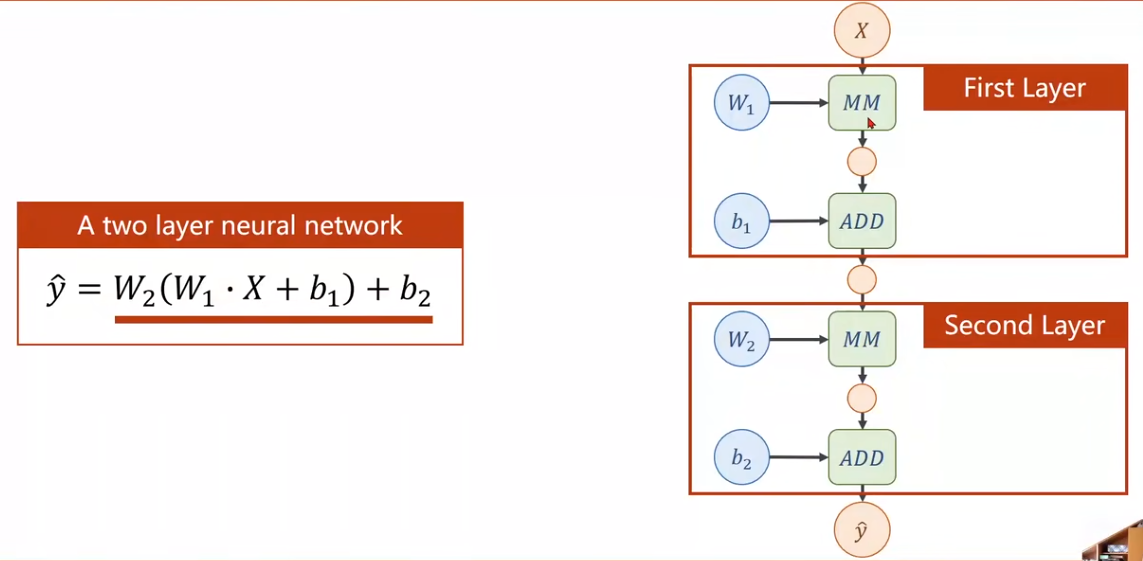 如图,表示一个两层的神经网络,其中MM表示矩阵的乘法。输入为
如图,表示一个两层的神经网络,其中MM表示矩阵的乘法。输入为
- 注意:从这里开始,处理的数据都是张量
- 这里还有一个问题,这个两层的神经网络通过整理后,得到
,等效为一层的神经网络。 因此,需要在每一层后添加一个非线性函数(激活函数),例如ReLU函数。后续会详细介绍。
3 Chain Rule
- Create Computational Graph(Forward)
- Local Gradient
- Given gradient from successive node
- Use chain rule to compute gradient(Backward)
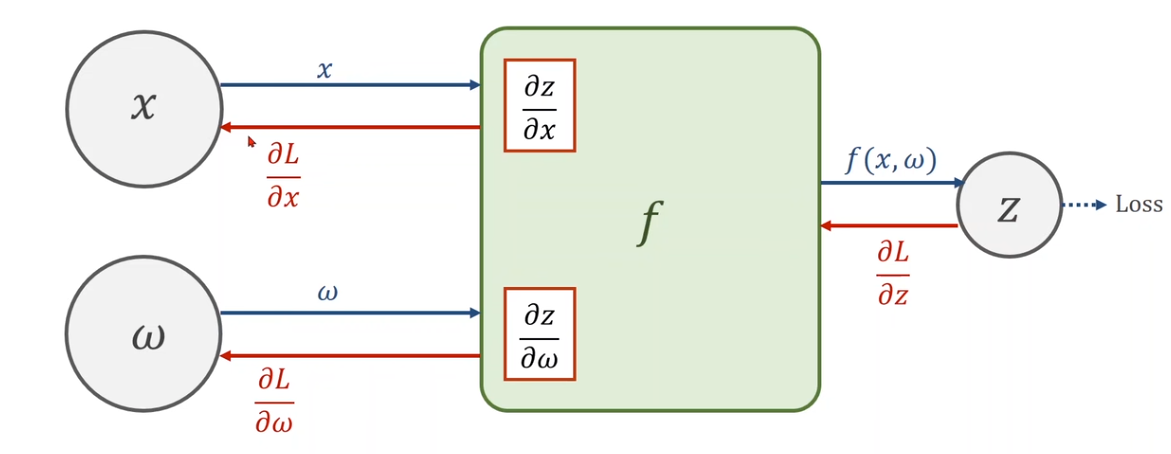
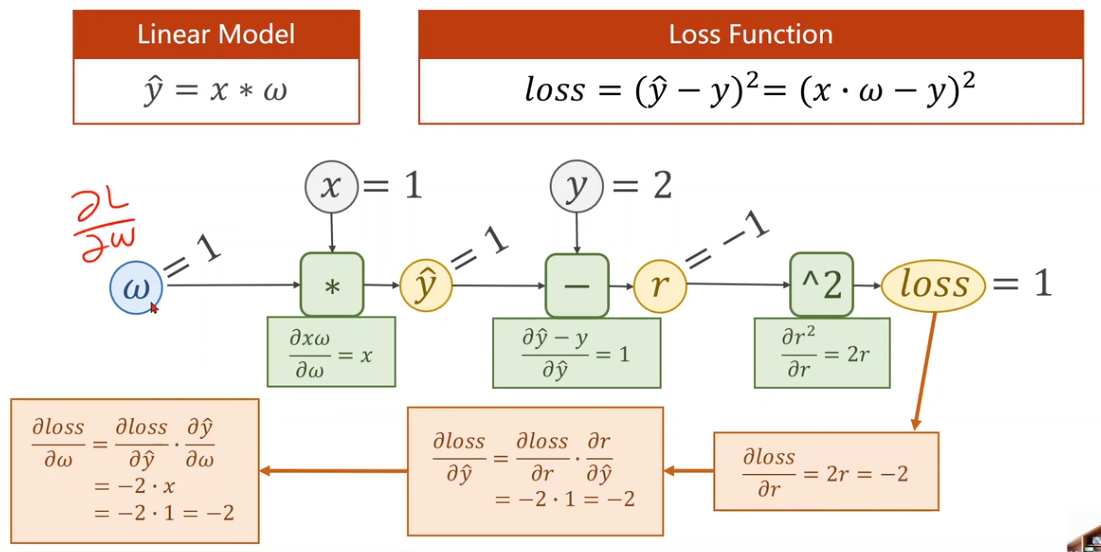
- 求梯度的最小单元是每个层的本地梯度,视定义的原子操作而定。
4 Tensor in Pytorch
tensor(张量)是pytorch中最基本的数据结构,它是一个多维数组,用于存储和操作数据。
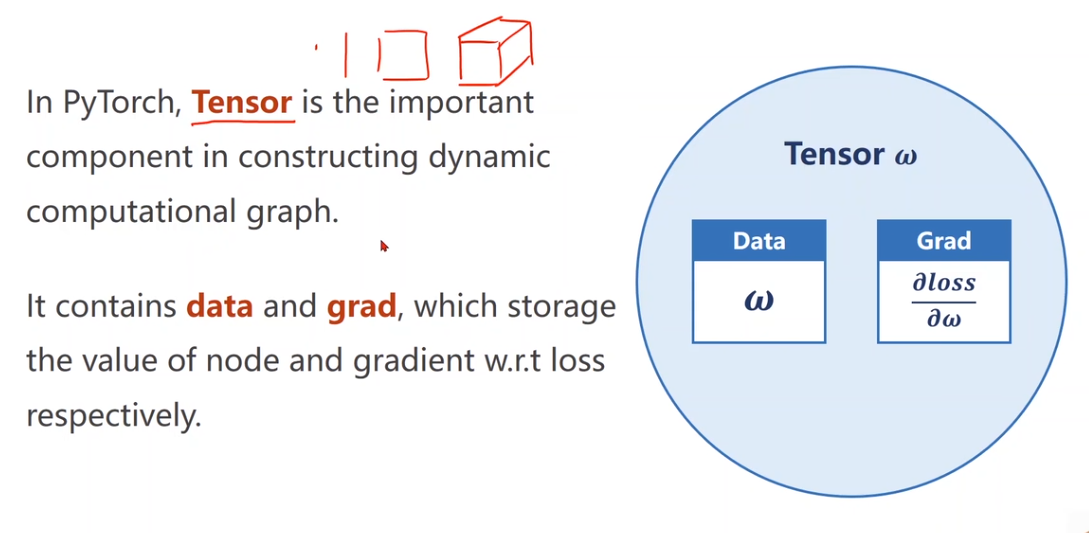
- 如图,tensor类型中包括Data本身以及梯度值。 Implementation
1 | |
PyTorch入门学习:4-Back Propagation
https://eleco.top/2026/02/24/learn-torch-4-Back-Propagation/