1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| class DiabetesDataset(Dataset):
def __init__(self):
xy=np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
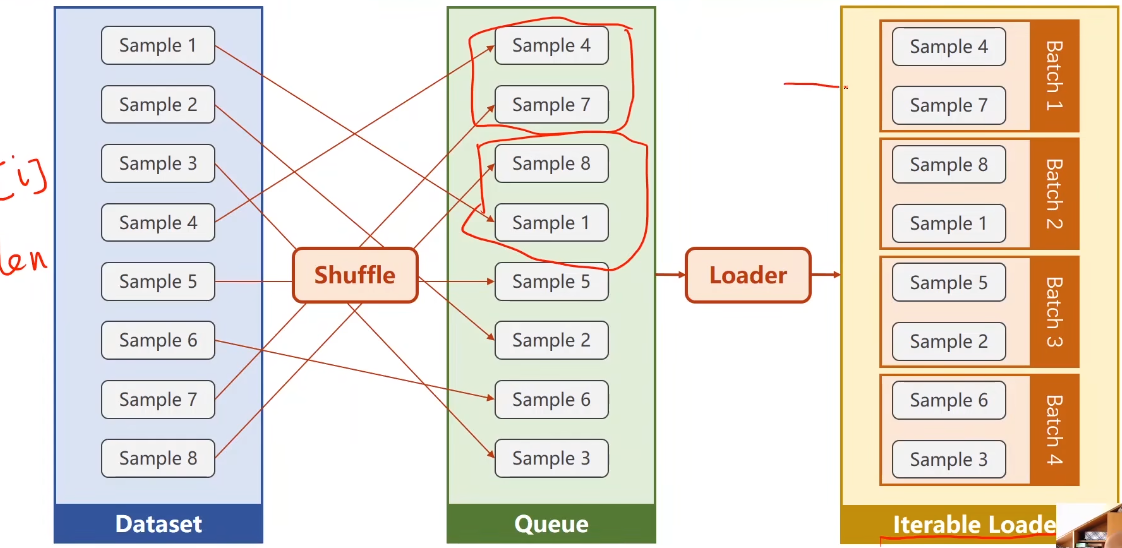
dataset = DiabetesDataset('data/diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
inputs, labels = data
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(f'Epoch: {epoch} | Batch: {i} | Loss: {loss.item()}')
optimizer.zero_grad()
loss.backward()
optimizer.step()
|
 Example: MNIST
Example: MNIST