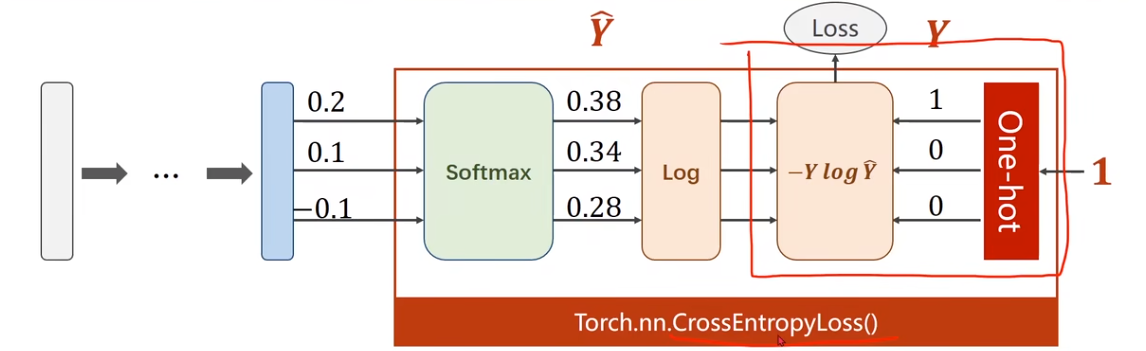
9 Softmax Classifier
1 Introduction
Sigmoid换为Softmax层。
2 Softmax Layer
Softmax函数
An example
3 Loss Function - Cross
Entropy
不难看出损失只对标签为一的一项有效,假设
1 2 3 4 5 6 7 import numpy as np1 , 0 , 0 ])0.2 , 0.1 , -0.1 ])sum ()sum (y * np.log(y_pred))print (loss)
注意:
如图,在PyTorch中,CrossEntropyLoss已经包含了Softmax层,因此在使用时不需要手动添加Softmax层。另外,使用One-Hot编码表示标签,需要使用LongTensor类型。
1 2 3 4 5 6 7 import torch0 ])0.2 , 0.1 , -0.1 ]])print (loss)
4 MNIST Dataset
4.1 数字图像
数字图像是指由像素点组成的二维图像,每个像素点都有一个数值来表示其颜色或灰度值。灰度图像是指每个像素点只有一个数值(单通道(channel)),而不是RGB三通道的数值。
h - 高度 | w - 宽度 | c - 通道 在PIL(Python Imaging
Library)和opencv中,图像张量是PyTorch中,图像张量是
MNIST数据集中的样本是28x28的灰度图像,每个像素值在
4.2 Import and Prepare
Dataset
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import torchfrom torchvision import datasets, transformsfrom torch.utils.data import DataLoaderimport torch.nn.functional as Fimport torch.optim as optim64 0.1307 ,), (0.3081 ,))'../dataset/mnist' , True , True )True )'../dataset/mnist' , False , True )False )
4.3 Design Model
x=x.view(-1, 28*28)中的-1表示自动计算该维度的大小,这里是将这次使用的激活函数为更常用的relu函数。relu函数的定义为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Net (torch.nn.Module):def __init__ (self ):super (Net, self ).__init__()self .l1 = torch.nn.Linear(784 , 512 )self .l2 = torch.nn.Linear(512 , 256 )self .l3 = torch.nn.Linear(256 , 128 )self .l4 = torch.nn.Linear(128 , 64 )self .l5 = torch.nn.Linear(64 , 10 )def forward (self, x ):1 , 28 *28 )self .l1(x))self .l2(x))self .l3(x))self .l4(x))self .l5(x)return x0.01 , momentum=0.5 )
关于动(冲)量的设置 传统梯度下降:
加速收敛:在一致的方向上积累速度,加快收敛
减少震荡:平滑路径,减少在局部最小值附近的震荡
穿越鞍点:帮助模型更快地穿越梯度较小的区域
4.4 Train and Test
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def train (epoch ):0.0 for batch_idx, data in enumerate (train_loader, 0 ):if batch_idx % 300 == 299 :print ('[%d, %5d] loss: %.3f' %1 , batch_idx + 1 , running_loss / 300 ))0.0 def test ():0 0 with torch.no_grad():for data in test_loader:max (outputs.data, dim=1 )0 )sum ().item()print ('Accuracy on test set: %d %%' % (100 * correct / total))if __name__ == '__main__' :for epoch in range (10 ):
为什么准确率不太高?
目前使用的是全连接层,而加入特征提取算法 能够提取图像的高层特征,在图像识别任务中更有效。
一些人工特征提取算法:FFT、wavelet等
自动特征提取算法:卷积神经网络(CNN)等
5 Exercise
5.1 Cross Entropy Loss vs
NLLLoss
What are the differences between CrossEntropyLoss and
NLLLoss?
Reading the document:
Try to know why:
CrossEntropyLoss <===> LogSoftmax + NLLLoss
5.2 Classifier Implementation
Try to implement a classifier for:
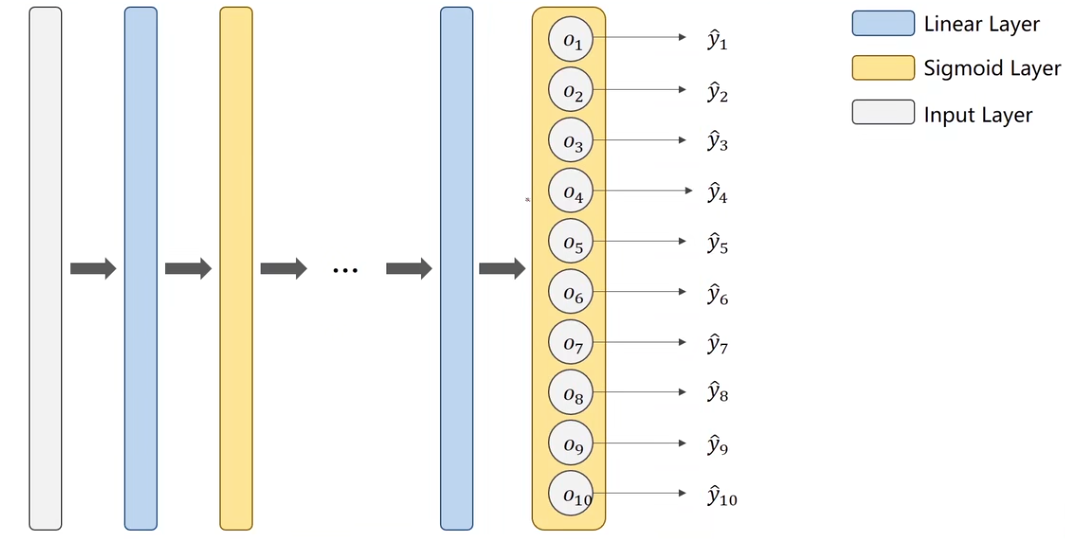 如果直接使用之前的模型,每个输出对应相应类别的概率,那么会造成最终输出不满足分布的特点。
因此,需要对输出进行处理,使得每个类别对应的输出满足以下条件:
如果直接使用之前的模型,每个输出对应相应类别的概率,那么会造成最终输出不满足分布的特点。
因此,需要对输出进行处理,使得每个类别对应的输出满足以下条件: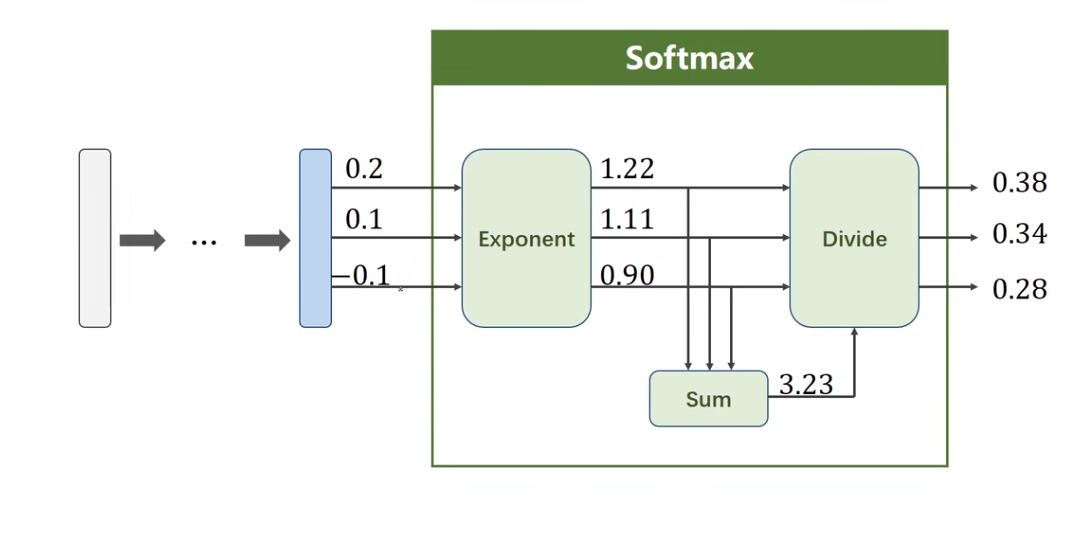
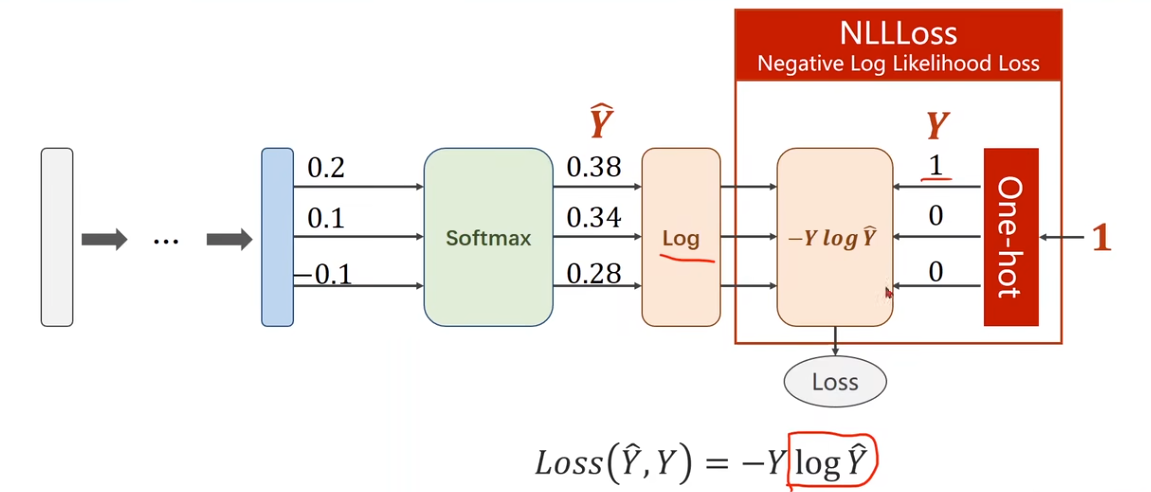 Cross Entropy Loss Function:
Cross Entropy Loss Function: