PyTorch入门学习:11-Advanced CNN
11 Advanced CNN
1 GoogLeNet
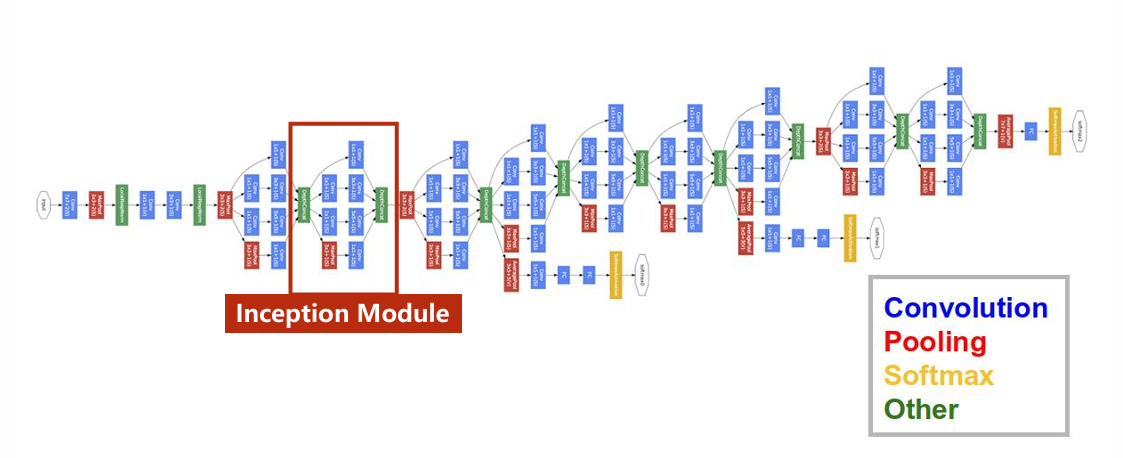 如图,是常见的神经网络
如图,是常见的神经网络GoogLeNet。
为了降低编写难度和维护成本,需要减少代码冗余,因此将网络中多次出现的部分定义为一个类,称为Inception Module。
2 Inception Module
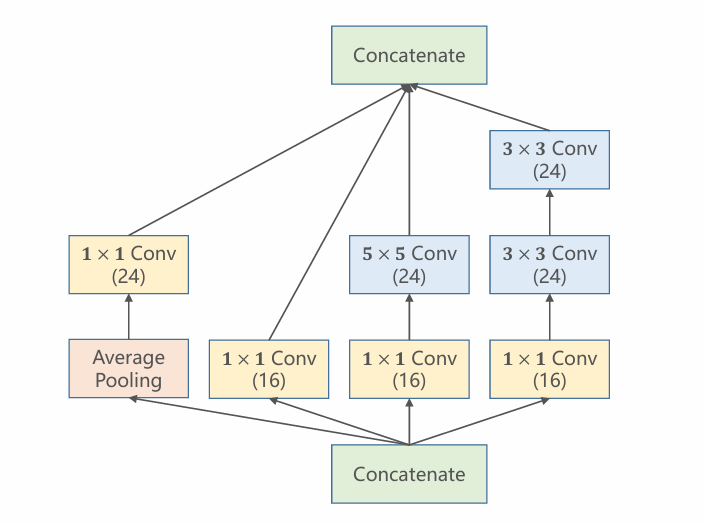 如图所示,是
如图所示,是Inception Module的具体结构。
- 在块中使用了不同大小的kernel,将结果拼接在一起,视结果决定各个kernel的权重,得到最优组合。
- Concatenate:
拼接张量,同时为了正常拼接,需要设置stride和padding使张量保持相同的
,或者使用 convolution - Average Pooling: 平均池化
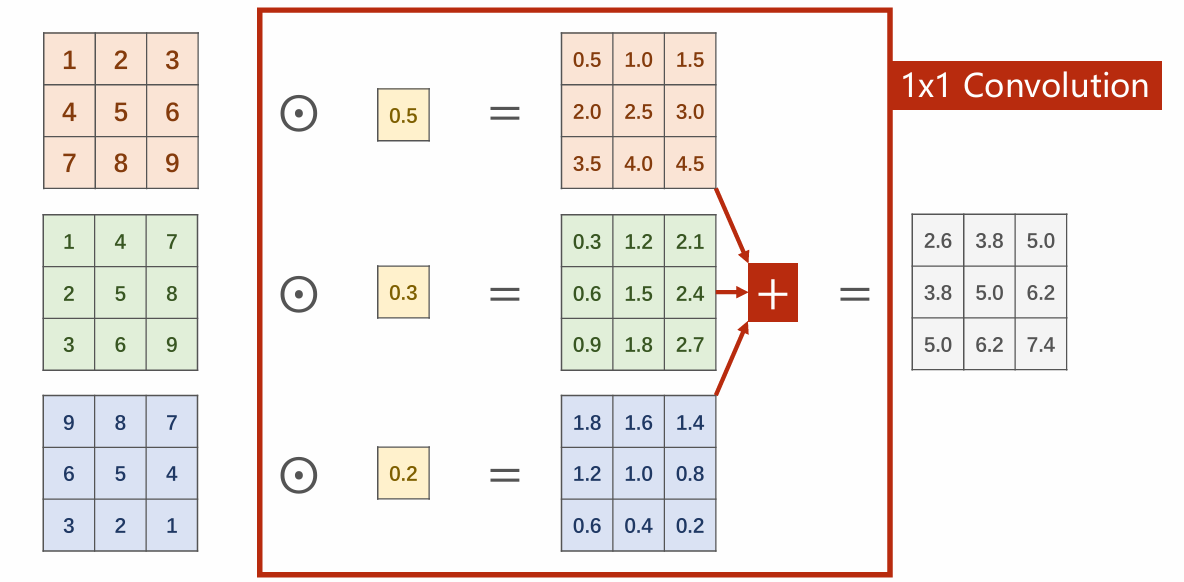
convolution: 如图所示,对每个像素点进行乘法操作,起到信息融合(同像素通道间)的作用。 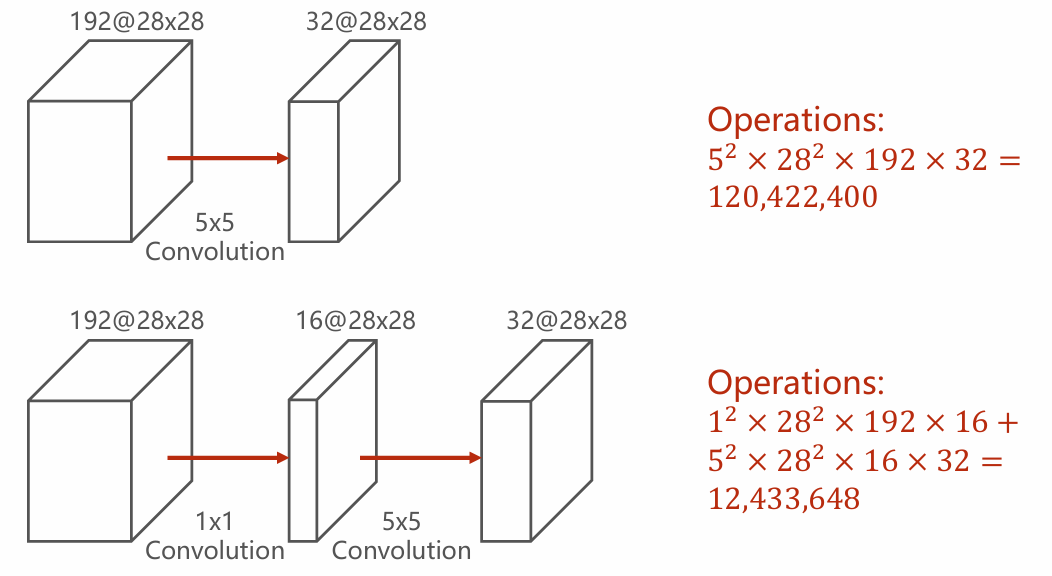
- Why
convolution? 如图,这种方式能够显著降低了运算的开销,可以使最终训练时设定更多的轮数。
3 Implementation of Inception Module
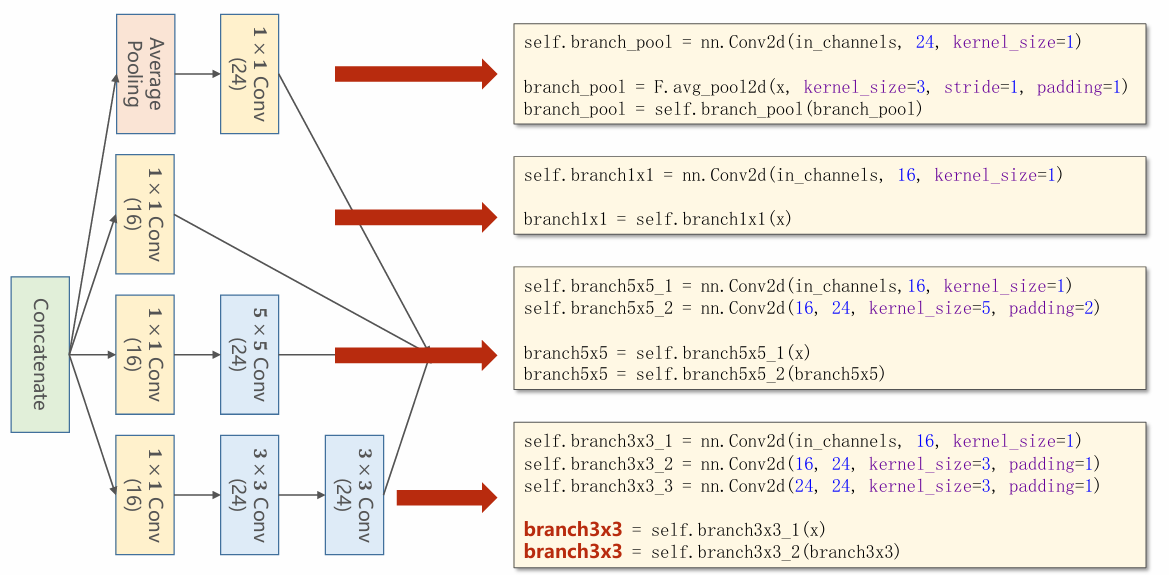
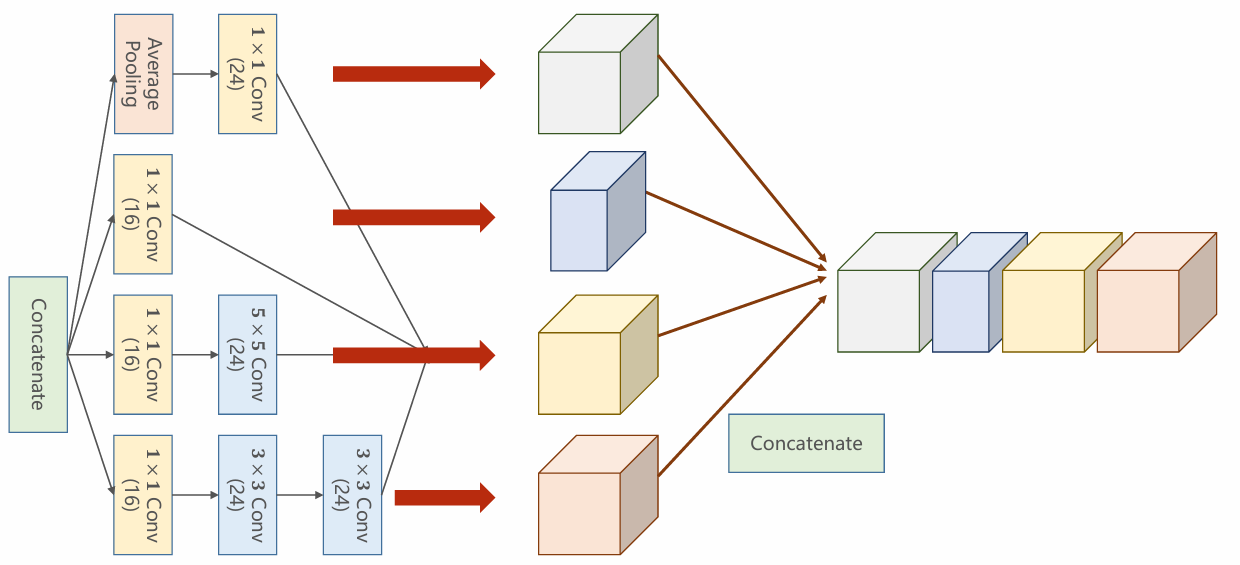
- 如图,concatenate操作是对张量的通道维度进行拼接。
1 | |
完整实现:
1 | |
4 Can we stack layers to go deeper?
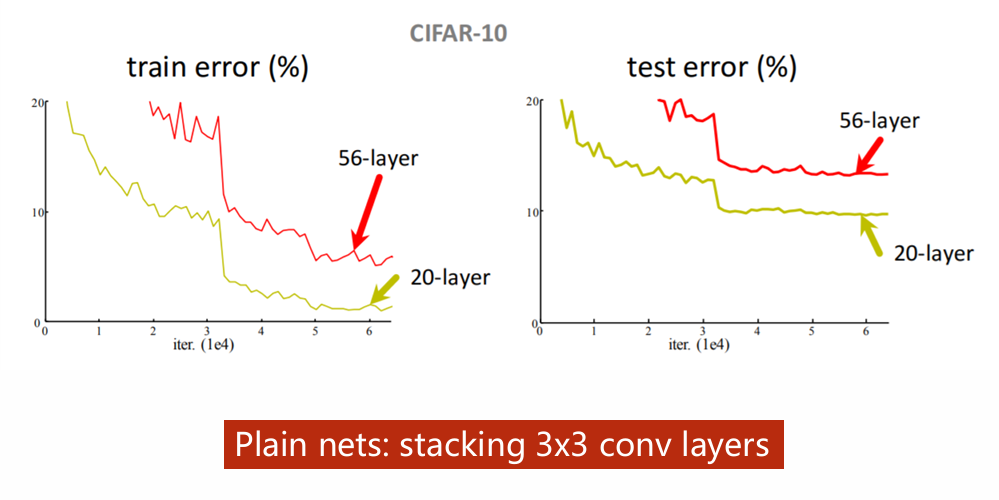 是不是网络层数越多,模型性能就越好呢?并不是。如图56层的网络在同一数据集(训练集和测试集)上的表现不如20层的网络。
这可能是梯度消失导致的,即梯度经过多次的相乘,越来越小,最终使权重的更新变得很慢,在有限的轮次中很难得到有效的训练。
是不是网络层数越多,模型性能就越好呢?并不是。如图56层的网络在同一数据集(训练集和测试集)上的表现不如20层的网络。
这可能是梯度消失导致的,即梯度经过多次的相乘,越来越小,最终使权重的更新变得很慢,在有限的轮次中很难得到有效的训练。
- 怎样解决梯度消失问题? 可以使用逐层训练的方法,每训练一层就将其权重固定,再继续训练下一层。
5 Deep Residual Learning
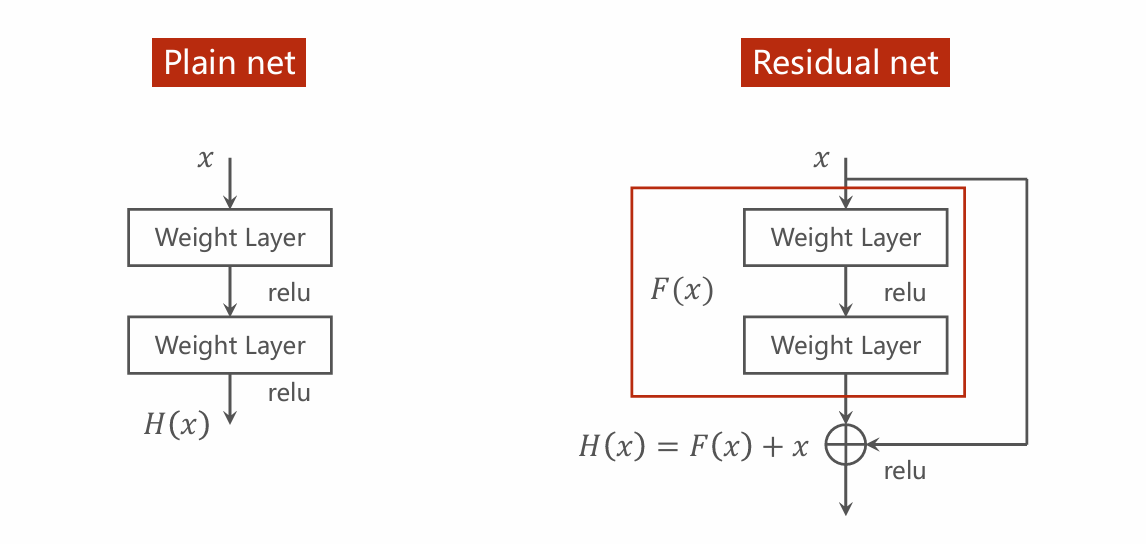 Residual
Network(残差网络)将输出与输出相加形成一个新的输出,通过这种方式,求得的梯度回避原先的梯度多1,能够有效避免梯度消失的问题。如图,就是residual网络的组成单元。显然,在这个单元中,输入张量的维度需要与输出张量的维度保持一致。
Residual
Network(残差网络)将输出与输出相加形成一个新的输出,通过这种方式,求得的梯度回避原先的梯度多1,能够有效避免梯度消失的问题。如图,就是residual网络的组成单元。显然,在这个单元中,输入张量的维度需要与输出张量的维度保持一致。
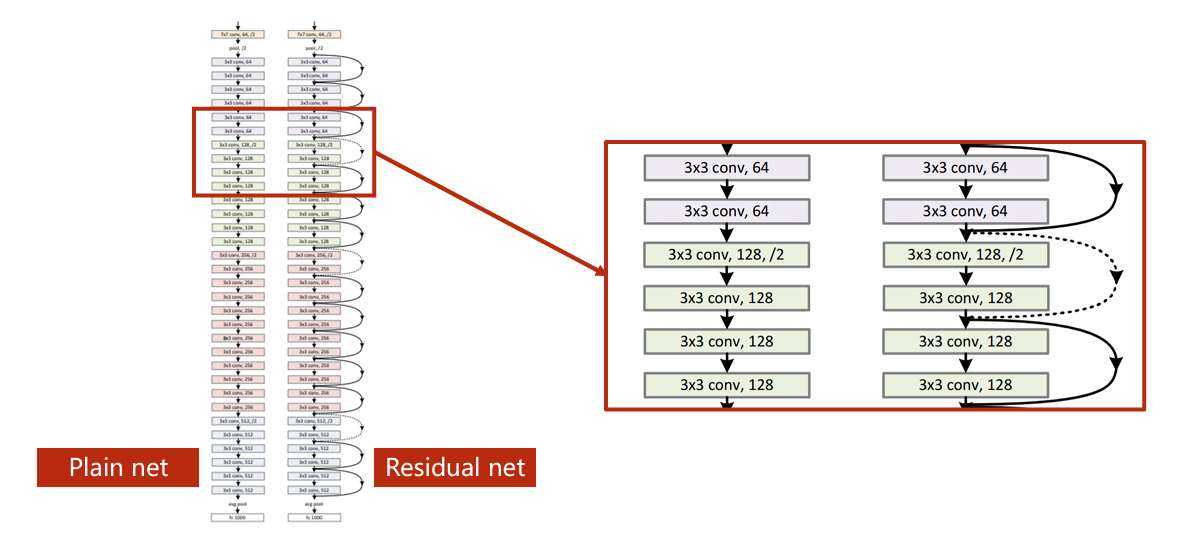 如图,是使用该思想搭建的网络结构ResNet。
Implementaion
如图,是使用该思想搭建的网络结构ResNet。
Implementaion 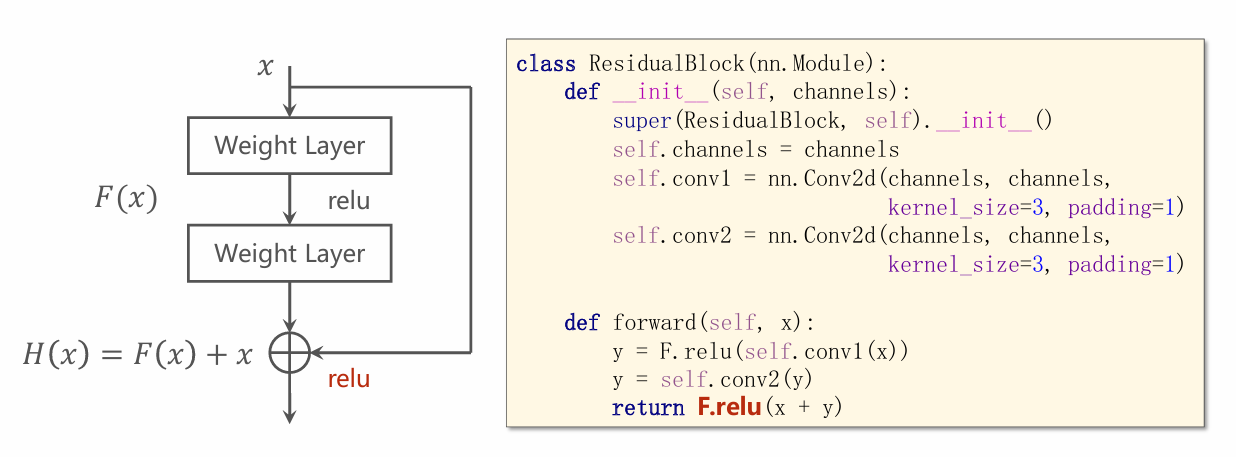 如图,将Residual Block封装为一个类。
如图,将Residual Block封装为一个类。

6 Exercise
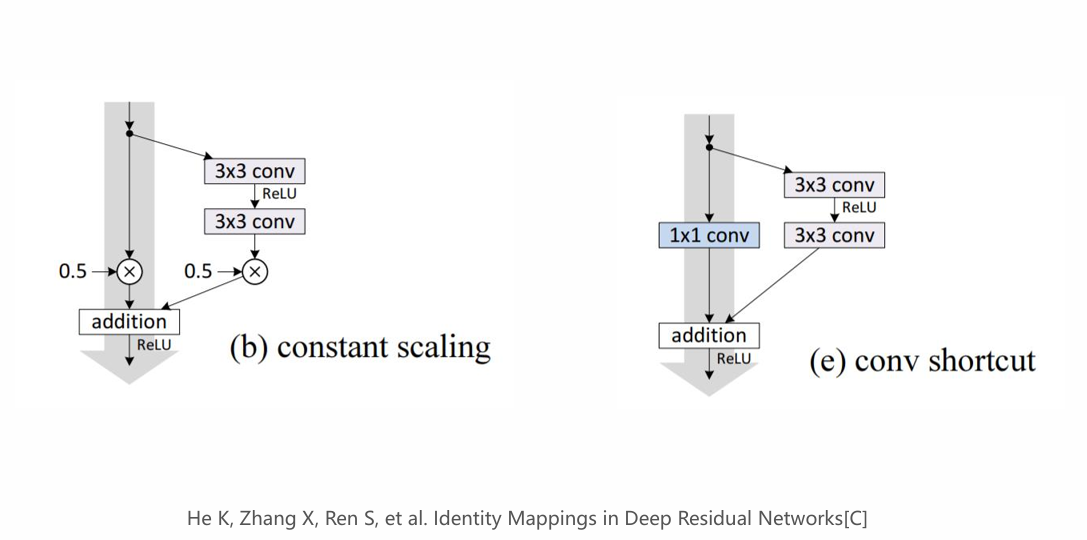
- Reading Paper and Implementing
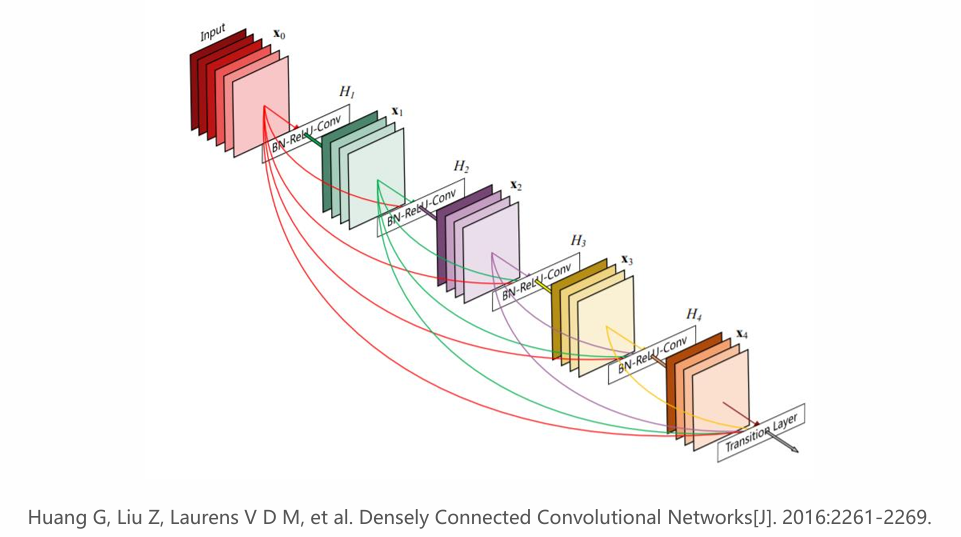
- Reading and Implementation DenseNet
建议:
- 阅读《深度学习》,掌握理论知识。
- 通读PyTorch文档。
- 复现经典工作(不是直接使用开放的代码)(遇到困难再阅读),大量阅读论文。
- 扩充视野(在前几条的基础上,一般遇到简单的块可以不去实现,遇到不会实现的块就去阅读代码)。
PyTorch入门学习:11-Advanced CNN
https://eleco.top/2026/03/03/learn-torch-11-Advanced-CNN/